This content is from the fall 2016 version of this course. Please go here for the most recent version.
Analyzing Text in Python
Joshua G. Mausolf
November 8, 2016
Prerequisites:
If you have not already done so, you will need to properly install an Anaconda distribution of Python, following the installation instructions from the first week.
I would also recommend installing a friendly text editor for editing scripts such as Atom. Once installed, you can start a new script by simply typing in bash atom name_of_your_new_script. You can edit an existing script by using atom name_of_script. SublimeText also works similar to Atom. Alternatively, you may use a native text editor such as Vim, but this has a higher learning curve.
Note: If atom does not automatically work, try these solutions.
Installing New Python Packages
If you do not have a package, you may use the Python package manager pip (a default python program) to install it. Note that pip is called directly from the Shell (not in a python interpreter).
To begin, update pip.
On Mac or Linux
pip install -U pip setuptoolsOn Windows
python -m pip install -U pip setuptoolsTo see further prerequisites, please visit the tutorial README.
Analyzing Text in Python
There are many ways to analyze text in Python. One popular package is NLTK. We can actually perform simple analysis of text without NLTK. This module does just that. In particular, we can search a set of text files for one or more keywords and phrases, count the occurrence of those terms, and save the results as a CSV. That data can be visualized using standard methods to produce graphs such as the one below:
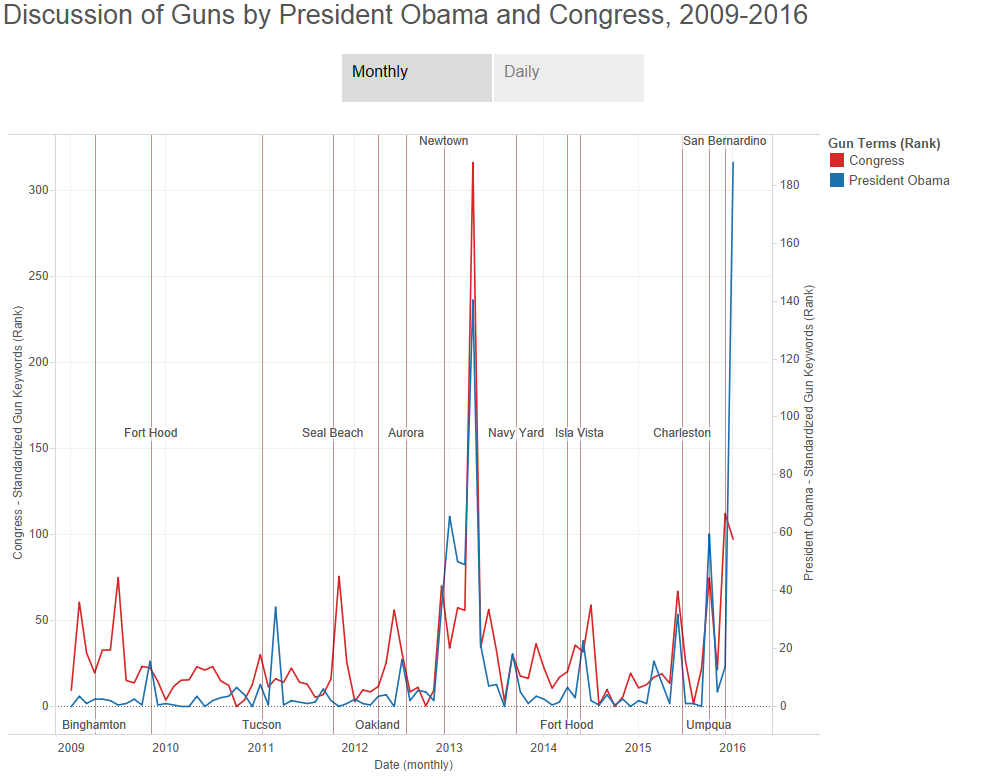
Looking Under th Hood
The full text_keyword_classifier.py script is available on Github.
One of the main ways the code runs is by searching for ngrams, or particular phrases like pay the fair share, in this an ngram of length 4. In Python, we can count ngrams with a series of functions:
def group_text(text, group_size):
"""
This function groups a text into text groups.
It returns a list of grouped strings.
"""
word_list = text.split()
group_list = []
for k in range(len(word_list)):
start = k
end = k + group_size
group_slice = word_list[start: end]
# Append only groups of proper length/size
if len(group_slice) == group_size:
group_list.append(" ".join(group_slice))
return group_list
def get_group_set(group_size, text):
group_list = group_text(text, group_size)
group_set = set(group_list)
return group_set
def ngram(n, data):
ngram = get_group_set(n, data)
return ngram
def speech_phrase_counter(ngram1, ngram2, ngram3, ngram4, terms, df, n, sent):
for term in terms:
for gram in ngram4:
if term == gram:
count = sent.count(gram)
df.ix[n, term] = count
for gram in ngram3:
if term == gram:
count = sent.count(gram)
df.ix[n, term] = count
for gram in ngram2:
if term == gram:
count = sent.count(gram)
df.ix[n, term] = count
for gram in ngram1:
if term == gram:
count = sent.count(gram)
df.ix[n, term] = count
These functions come together in the speech_classifier function, which loops over numerous speech files and writes the results to a CSV. While this function is complex, the key implementation of the above utility functions comes together in the following step:
for speech in speech_files:
#(Parts of Script Omitted for Clarity)
sent = read_speech(speech)
#Add Keyword Data
ngram1 = get_group_set(1, sent)
ngram2 = get_group_set(2, sent)
ngram3 = get_group_set(3, sent)
ngram4 = get_group_set(4, sent)
#Count Keywords
speech_phrase_counter(ngram1, ngram2, ngram3, ngram4, terms, df, n, sent)
Running the Example
Git clone this repository:
git clone https://github.com/jmausolf/Python_Tutorials/Navigate to the Python Scripts folder in this repository and run the example:
cd Text_Keyword_Counter python find_keywords.py
Modifying the Keywords for Your Purposes:
The full find_keywords.py script is available on Github.
To run the code, there are two steps:
1. Define Your Keywords
2. Run the Program
Below are some examples:
1. DEFINING YOUR KEYWORDS
Example 1: Keyword Categories with Keywords/Phrases
You can make one or more keyword lists to search:
word_list_one = ["United States", "Canada"]
word_list_two = ["economy", "war"]
combined_terms = word_list_one+word_list_twoExample 2: Discussion of Guns and Shootings
guns = ["_start", "firearm", "guns", "gun", "automatic weapons", "automatic weapon", "cheap handguns", "handguns", "shotgun", "shotguns", "rifle", "rifles", "Saturday night special", "high capacity magazines", "assualt rifles", "sawed off shotguns", "silencers", "AK-47s", "AR15", "AR-15s", "Glock", "Glocks"]
gun_laws = ["Second Amendment", "right to bear arms", "gunshow loophole", "gunshow", "gun dealer", "gun ownership", "gun sales", "gun manufacturers", "background check", "concealed carry", "ATF", "National Rifle Association", "NRA"]
gun_violence = ["mass shooting", "shootings", "guns don't kill people", "gun violence", "gunned down"]
shootings = ["Newtown", "San Bernardino", "Blacksburg", "Navy Yard", "Aurora", "Tucson", "Virginia Tech", "Fort Hood", "Charleston", "_end"]
gun_terms = guns+gun_laws+gun_violence+shootings2. RUN THE PROGRAM
from text_keyword_classifier import *
#Example Searching for Keywords in Presidential Data
speech_classifier("data/president", 0, 10, "White_House_data.csv", gun_terms, 1)# In the Shell:
python find_keywords.pyWhat are these function inputs?
In short, the first parameter "data/president" defines where your data is located. 0, 10 describes the file name slice to implement. Here, the files have dates embedded such as “2011-09-17_ID1.txt”. 0, 10 correctly extracts the date from the file name. "White_House_data.csv" is the filename to save your results. gun_terms are defined above. These are your keywords. 1 selects the option to calculate NLTK metrics for the total number of words and tokens in a given speech file.
Full Function Documentation:
"""
---------------------------------------------------------------------
INSTRUCTIONS TO RUN THE PROGRAM
---------------------------------------------------------------------
- (1) To run the function, first define your full keyword list.
Several examples are above.
---------------------------------------------------------------------
- (2) Next, select the folder with the speech files.
---------------------------------------------------------------------
- (3) Outline the string slice that contains the date for your
text file.
Your text file should contain a date of the file
for example, 2011-09-17_ID1.txt or CREC-2015-01-03.txt.
- ds1:ds2 = - date slices of filenames
E.g. the filename "2011-09-17_ID1.txt"
would want date slices of
ds1 = 0 and ds2 = 10
This takes the string slice 0:10
and provides a date = 2011-09-17
---------------------------------------------------------------------
- (4) Specify the name of the output file.
---------------------------------------------------------------------
- (5) Specify other options if desired.
See further documentation under speech_classifier
documentation.
speech_classifier(folder_name, ds1, ds2, output_file, terms,
metric=0, addtime=0, addloc=0, addcite=0):
---------------------------------------------------------------------
"""This work is licensed under the CC BY-NC 4.0 Creative Commons License.