This content is from the fall 2016 version of this course. Please go here for the most recent version.
Machine Learning in Python
Joshua G. Mausolf
November 16, 2016
Prerequisites:
If you have not already done so, you will need to properly install an Anaconda distribution of Python, following the installation instructions from the first week.
I would also recommend installing a friendly text editor for editing scripts such as Atom. Once installed, you can start a new script by simply typing in bash atom name_of_your_new_script. You can edit an existing script by using atom name_of_script. SublimeText also works similar to Atom. Alternatively, you may use a native text editor such as Vim, but this has a higher learning curve.
Note: If atom does not automatically work, try these solutions.
Further documentation can be found on the tutorial README.
Machine Learning Tutorial
This module illustrates some basic machine learning in Python using Sci-Kit Learn.
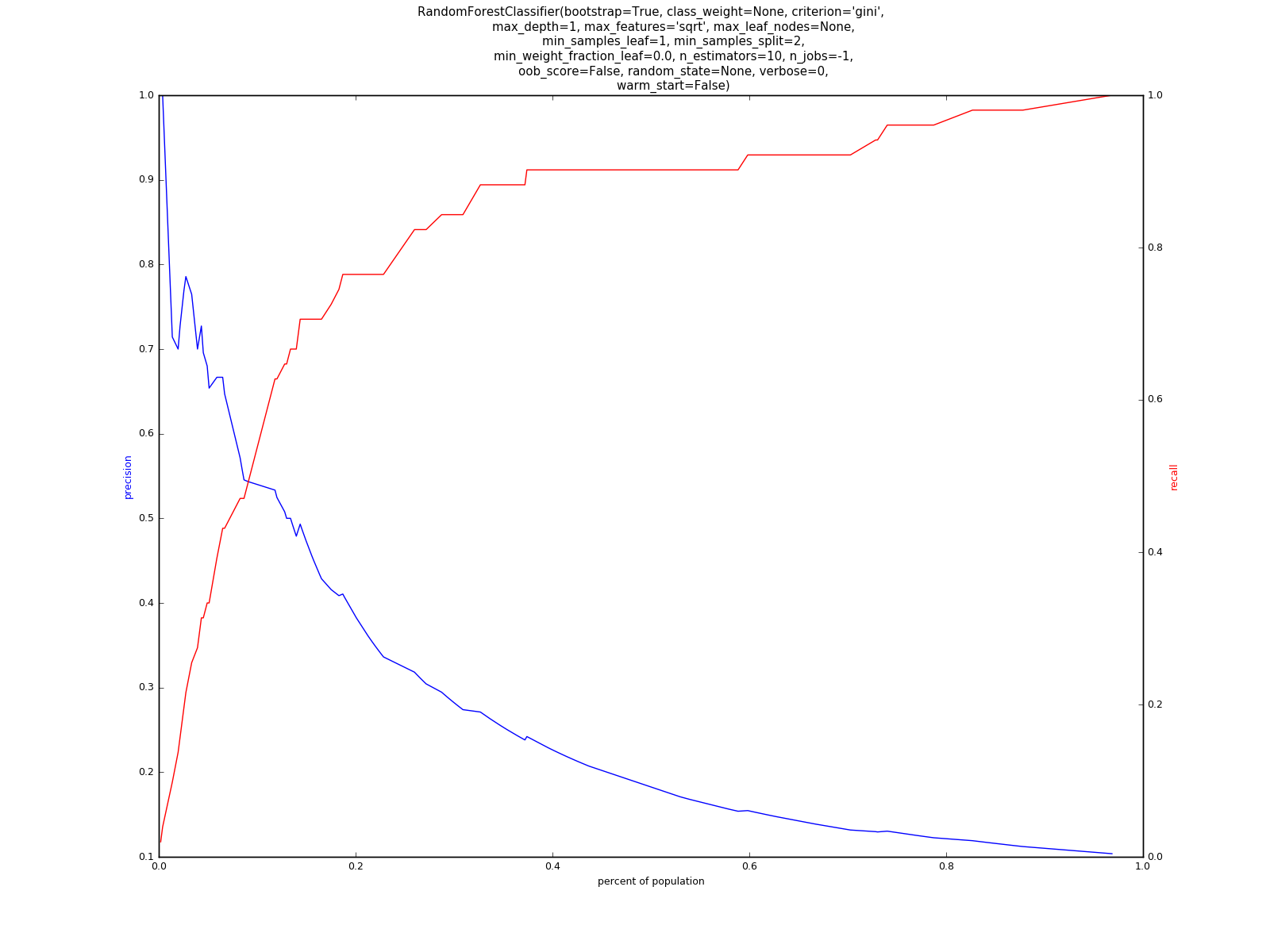
A fundamental principal is that we do not assume a priori that any single model will be best for the data. Instead, we loop over multiple classifiers and parameterizations. In this way, we can run hundreds of models and select the best one on a variety of metrics, such as precision and recall.
Example Precision-Recall Plot:
Quick Start Guide
Example data for this repository comes from the General Social Survey (GSS) 2014. More notes on the data preprocessing are detailed in the data folder.
To run the example (link to tutorial repository):
git clone --recursive https://github.com/jmausolf/Python_Tutorials
cd Python_Tutorials/Machine_Learning
python run.pyModifying The Details
To modify the default data, outcome variable, or parameters, open the run.py script with your favorite text editor, such as Atom, Sublime, or Vim. Here, you must specify the dataset (as .CSV), the outcome variable you would like to predict (for binary classification), and the features you would like to use to make the predictions.
Default Example:
#Define Data
dataset = 'file'
outcome = 'partyid_str_rep'
features = ['age', 'sex', 'race', 'educ', 'rincome']Once you edit these fields, save the script, and in terminal execute: python run.py
Note:
Your data may have hundreds of features (independent variables/predictors). If you would like to use all of them (and would rather not type write them all out explicitly) simply uses the --all_features option of the magic loop.
python run.py --all_features TrueOf course, an overlooked aspect thus far is feature development. The GSS data in the example is not in the ideal form. For example, most of the data is categorical. We might want to make indicators for each categorical column, calculate various aggregations or interactions, among other possibilities. An ideal data pipeline might make the changes to the feature set prior running this script.
Looking Under the Hood:
To understand the in’s and out’s of the magic loop (full code here), let’s first look at a very simple example of the example data on a single model:
from sklearn import metrics
from sklearn.ensemble import RandomForestClassifier
from sklearn.cross_validation import train_test_split
import pandas as pd
# Define Data
df = pd.read_csv('data/gss2014.csv', index_col=0)
outcome = 'partyid_str_rep'
features = ['age', 'sex', 'race', 'educ', 'rincome']
# Set, X, y, Train-Test Split
X, y = df[features], df[outcome]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
# Build Model and Fit
clf = RandomForestClassifier(n_estimators=10, max_depth=None,
min_samples_split=2, random_state=0)
y_pred = clf.fit(X_train, y_train).predict_proba(X_test)[:,1]
# Calculate Result
result = metrics.roc_auc_score(y_test, y_pred)
print(result)Here, we are fitting a Random Forest Model. Here, we set some arguments, such as n_estimators=10. We could have passed other parameter options such as n_estimators=5 or n_estimators=100. In the magic loop, we systematically loop over a set of options for n_estimators and other arguments. This process is repeated for other classifiers. In this way, we can estimate hundreds of models with relative ease.
Now that we have covered the basics, FORK this repository and analyze your own data.
Acknowledgements
This tutorial makes use of a modified submodule, originally forked from @rayidghani magicloops. It has been updated to run in Python2 or Python3. In addition, my modified fork modifies the plotting code and several of the functions to take a user-specified dataset, outcome variable, and features.
This work is licensed under the CC BY-NC 4.0 Creative Commons License.